⚓ 쿠버네티스 어나더 클래스 (지상편) - Spring 1, 2 을 듣고 작성하는 복습 블로그 입니다.
1. PV/PVC

1-1. PVC & PV 의 관계
- PVC : 사용자가 요청하는 스토리지 자원, 인터페이스 역할
- PV : 인프라 담당자가 제공하는 실제 스토리지 자원
- 연결 조건
- 필수 필드 :
- PVC : resources, accessModes
- PV : capacity, accessModes
- PVC 와 pv 는 selector 와 labels 를 통해 연결
- 필수 필드 :
1-2. PV 유형 : local
- local volume
- PV 의 local.path 에 실제 마운트 경로 지정
- 로컬 디스크를 스토리지로 사용
- 테스트 환경에서 많이 쓰는 방법
- 필수 속성 : nodeAffinity 속성
- 특정 Node 에 Pod 가 스케줄링되도록 지정
- 이유
- 로컬 디스크는 특정 노드에 존재
- Pod 가 다른 노드에 생성되면 해당 경로에 접근 불가능 → 오류 발생
- nodeAffinity 를 통해 Pod 를 반드시 해당 노드에 생성하도록 설정
- 예시
required:
nodeSelectorTerms:
- matchExpressions:
- {key: kubernetes.io/hostname, operator: In, values: [k8s-master]}
1-3. 테스트 환경에서 local PV 사용 이유
- 별도의 외부 스토리지 구축 번거로움
- 마스터 노드 등 특정 노드에 경로를 생성해 간이 스토리지로 사용
- 해당 경로 (path) 는 노드에 직접 만들어야 하며, Kubernetes 가 연결
1-4. PVC / PV 사용 목적
- 컨테이너 내부 파일은 Pod 삭제시 함께 사라짐
- 중요한 데이터는 외부 스토리지 (PV) 에 저장해야 삭제되지 않음
- PVC / PV 를 통해 Pod 가 죽어도 데이터 유지 가능
1-5. local 보다 더 쉽게 구축하기
- Pod 에 볼륨으로 hostPath 속성을 사용하는 것
- nodeSelector 라는 속성을 주면 노드를 지정할 수 있다
- 더 간결하고 많이 쓰이지만 주의사항이 있다.
- HostPath 볼륨에는 많은 보안 위험이 있으며, 가능하면 HostPath를 사용하지 않는 것이 좋다 (경고)
- 테스트 용으로 쓰기 편해서 이 속성을 저장 용도로 생각하기 쉽다.
- 하지만, 원래 노드에 있는 정보를 App 이 조회하는 용도로 용
- EX) Grafana 에서 Loki 로 모든 App 들의 로그를 볼 수 있었던 이유 실제 Pod 들의 Log 는 /var/log/pods 에 저장 Loki 의 promtail 이라는 Pod 가 hostPath 로 위 경로를 조회하고 있었기 때문에 가능
1-6. hostPath, local 사용 목적
- 노드의 정보를 이용해야 하는 기능의 App
- 테스트 환경에서 임시 저장 용도로 사용
- 운영 환경 X
- 노드 공간 부족해질 수 있다.
- 노드는 언제든지 죽을 수 있는 대상
1-7. 실습
- 파일 생성 API 호출
- 파일 생성 확인
- Pod 호출
- 파일 생성 확인
- hostPath 를 써서 사용
2. Deployment
App 에 새로운 버전이 나와서 업데이트를 해야할 때
→ 기존 Pod 는 삭제하고 새 Pod 를 배포
→ Deployment 의 strategy 속성으로 이 기능을 지원
2-1. strategy
- App 에 새로운 버전이 나와서 업데이트를 해아할 때 사용하는 속성
- 기존 Pod 는 삭제하고, 새 Pod 를 배포
- ReCreate, RollingUpdate
2-2. 업데이트 과정
template
- template 밑의 내용이 하나라도 변경되면 업데이트가 진행
- 모두 Pod 로 들어가는 내용이기 때문에 변경되면 그 내용으로 새로운 Pod 를 만든다.
업데이트 방식
- 새로운 이름의 ReplicaSet 을 만든다
- 기존 ReplicaSet 은 replicas 를 0 으로 만들어서 Pod 를 삭제
- 기존 ReplicaSet 은 삭제하지 않고, 문제가 생겨서 롤백 해야 될 때 사용

| Recreate | RollingUpdate |
| Pod 가 구동이 완료되기 전 Pod 삭제 | Pod 가 구동이 완료된 후 Pod 삭제 |
|
|

| maxUnavailable | maxSurge |
|
|
3. Service
3-1. 서비스 퍼블리싱
외부에서 Pod 로 트래픽 연결해주는 기능

type = NodePortport
- Node (MasterNode)
- port 가 만들어지면서 외부에서 보낸 트래픽을 쿠버네티스 내부에 Pod 로 전달 가능
- selector 과 label 로 Service 와 Pod 를 연결
- Pod의 컨테이너를 보면 App 이 기동 후 API, port 노출
- ports
- targetPort : 컨테이너 port
- nodePort : 여기 값으로 외부 포트가 만들어진다
- API 를 날리면 App 까지 트래픽 전달
type = ClusterIP (Default)
- 쿠버네티스 내부에 Pod에서만 접근하는 용도
3-2. 서비스 디스커버리
내부 DNS를 이용한 Service 이름으로 API 호출해주는 기능

- 서비스 이름이랑 80포트를 넣어서 API 를 호출 (http://api-tester-1231:80/version)
- → targetPort 로 포워딩돼서 트래픽이 Pod 로 전달
- Pod 와 Service 에는 생성될 때 IP 부여
- Pod 의 경우 삭제시 IP 가 변경 → 항상 Service를 통해 호출해야 한다
- Cluster의 다른 Namespace에 있는 Pod 호출
- Service 이름 뒤에 해당 Pod 가 속해있는 Namespace 이름까지
- http://api-tester-1231.anotherclass-123:80/version
컨테이너에 port가 변경되어도 Service는 신경쓰지 않도록
- App port 가 변경되면 Service의 targetPort 도 변경
- Pod 내에 ports 속성
- name : port 의 속성
- containerPort : 실제 App 이 나타내는 port
- contianerPort 속성을 줘야지 Pod 로 API 를 호출했을 때 App 이 트래픽을 받는건 🙅♀️
- contrainerPort 는 정보성인 속성
- targetPort 에 8080이 아니라 http를 넣을 수 있다
- Service 호출 시 Pod 에서 이름이 매핑된 포트를 찾아
- 그 port 로 API 를 호출
3-3. 서비스 레지스트리
Pod IP 관리
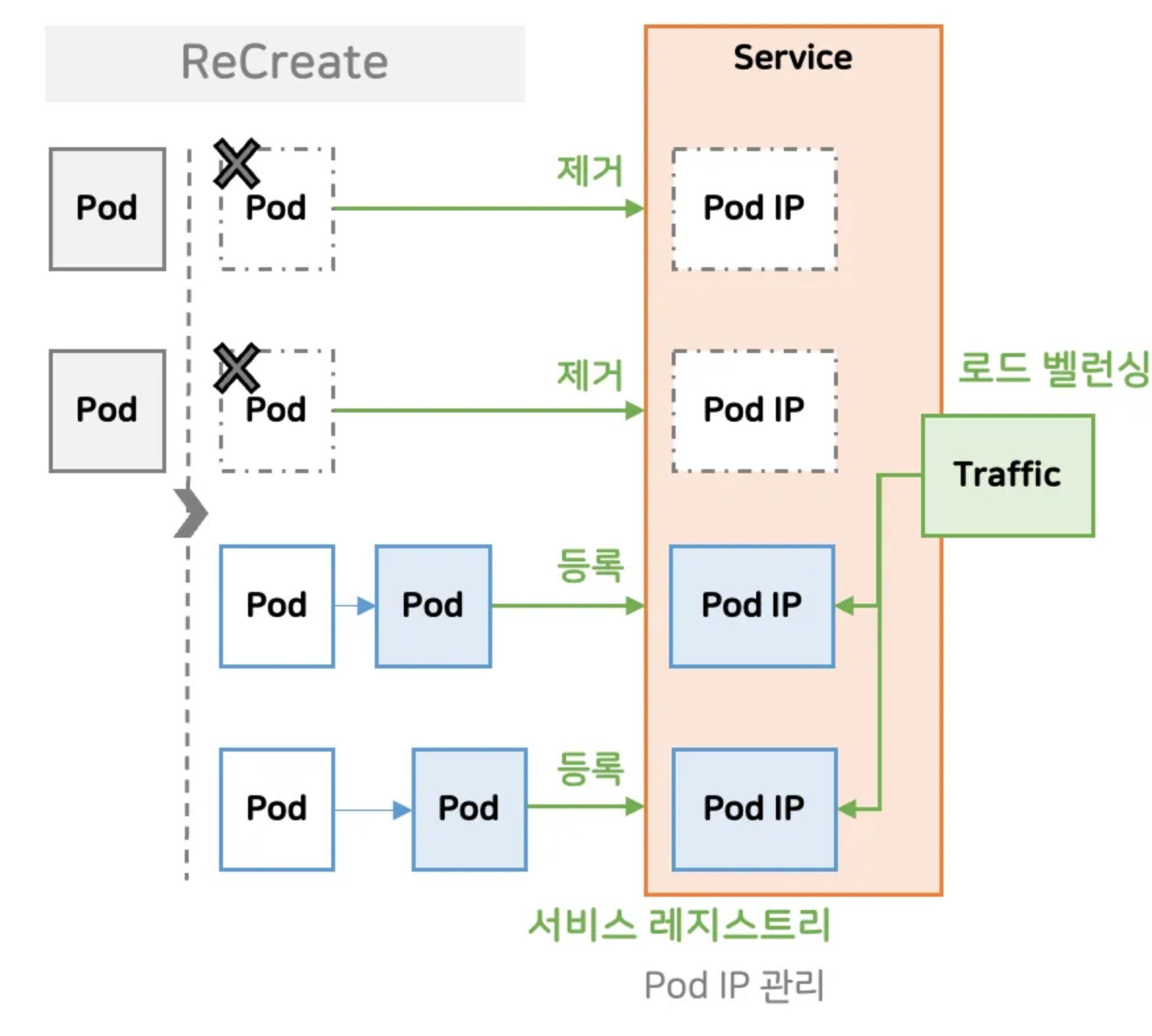
- Pod 가 삭제되고, 새로 만들어진다
- 쿠버네티스가 서비스에 호출되는 IP 를 제거하고, 등록
- Pod 에 Service만 연결해주면 Pod 호출을 신경쓰지 않아도 된다
- Service 에 트래픽을 날리면 트래픽을 분배해주는 로드 밸런싱 기능
3-4. 동작 확인 순서
- 서비스 디스커버리 확인
- Pod 내부에서 API 날려보기
- 설정 변경
- (기존) Pod ports name: http, Service ports targetPort : http
- 삭제 후 Service를 8080 으로 변경 후 API 날려보기
- containerPort 가 정보성 역할로 사용되는 걸 확인
4. HPA
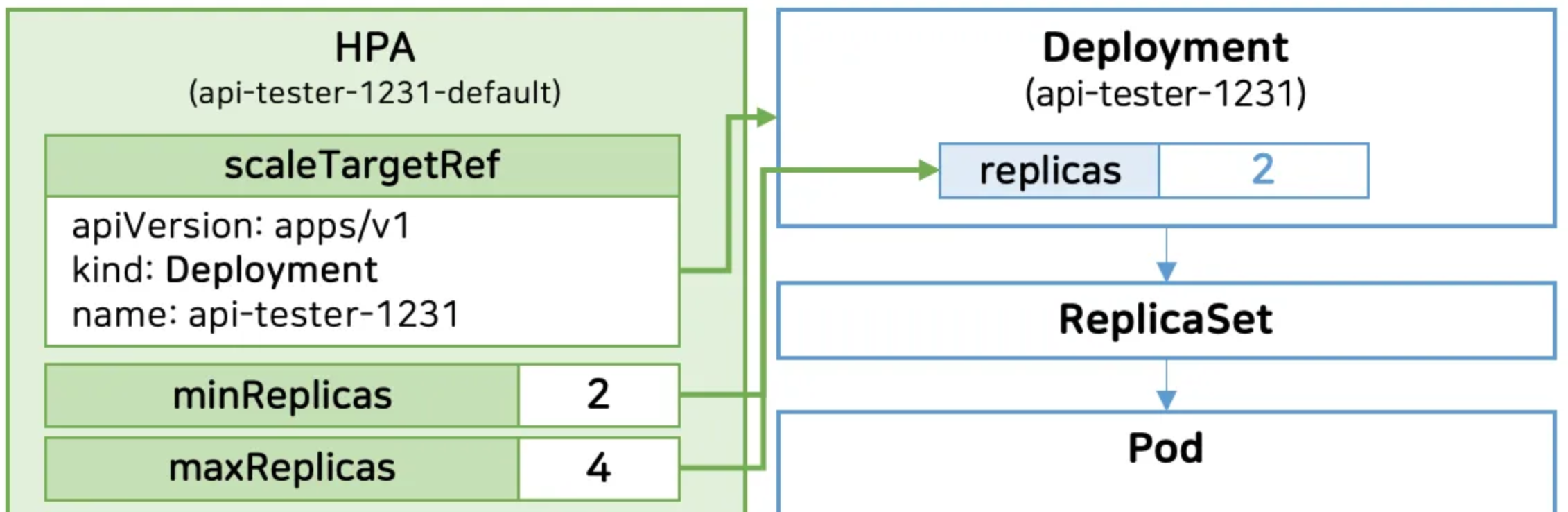
- scaleTargetRef : Deployment 를 지정
- 부하시 min/maxReplicas 범위 내에서 변경
4-1. metrics
- cpu 가 평균 60% 기준으로 스켈링 되도록 설정
- Pod 의 resource 와 관련된 내용
- requests : HAP 에서 100% 계산을 위한 기준 값
- container 내부에는 App 이 실행
- App 에서 실제 사용 중인 cpu 계산
- 기준 값을 넘으면 스케일링 아웃
- 계산 공식 : 현재 Pod 수 * (평균 CPU / HPA CPU)
- 변경될 Pod 의 수가 도출된다
- limits : cpu 최대 메모리
- HPA 의 평균 임계치를 결정하는데 큰 영향을 준다
- memory : 사용 상황에 따라서 변하는 값이 아니라 부하에 따른 증감 대상이 아니다
- HPA 에서 제공하는 옵션이지만 거의 사용하지 않는다
- 내부에서 GC 를 통해 메모리를 자동 정리
→ HPA 는 기본 기능으로 cpu 밖에 쓸게 없는데 cpu만 가지고 모든 어플리케이션 부하 상태를 판단하기 어렵다
→ 이럴 경우에는 써드파티앱을 사용해야 한다
4-2. 이상적인 스케일링

- 처음 Pod 두 개가 서비스 되고 있는 상태
- 부하가 꾸준히 증가 하고 있다
- 평균 60%가 넘으면 스케일 아웃
- Pod 하나가 새로 만들어지고, 기동이 완료되면 평균 부하가 떨어진다
- 트래픽이 감소되면, 서서히 부하가 낮아지기 시작한다.
- 일정 구간 밑으로 떨어지면 스케일인이 일어나면서 Pod 가 하나 삭제
4-3. 현실적인 스케일링
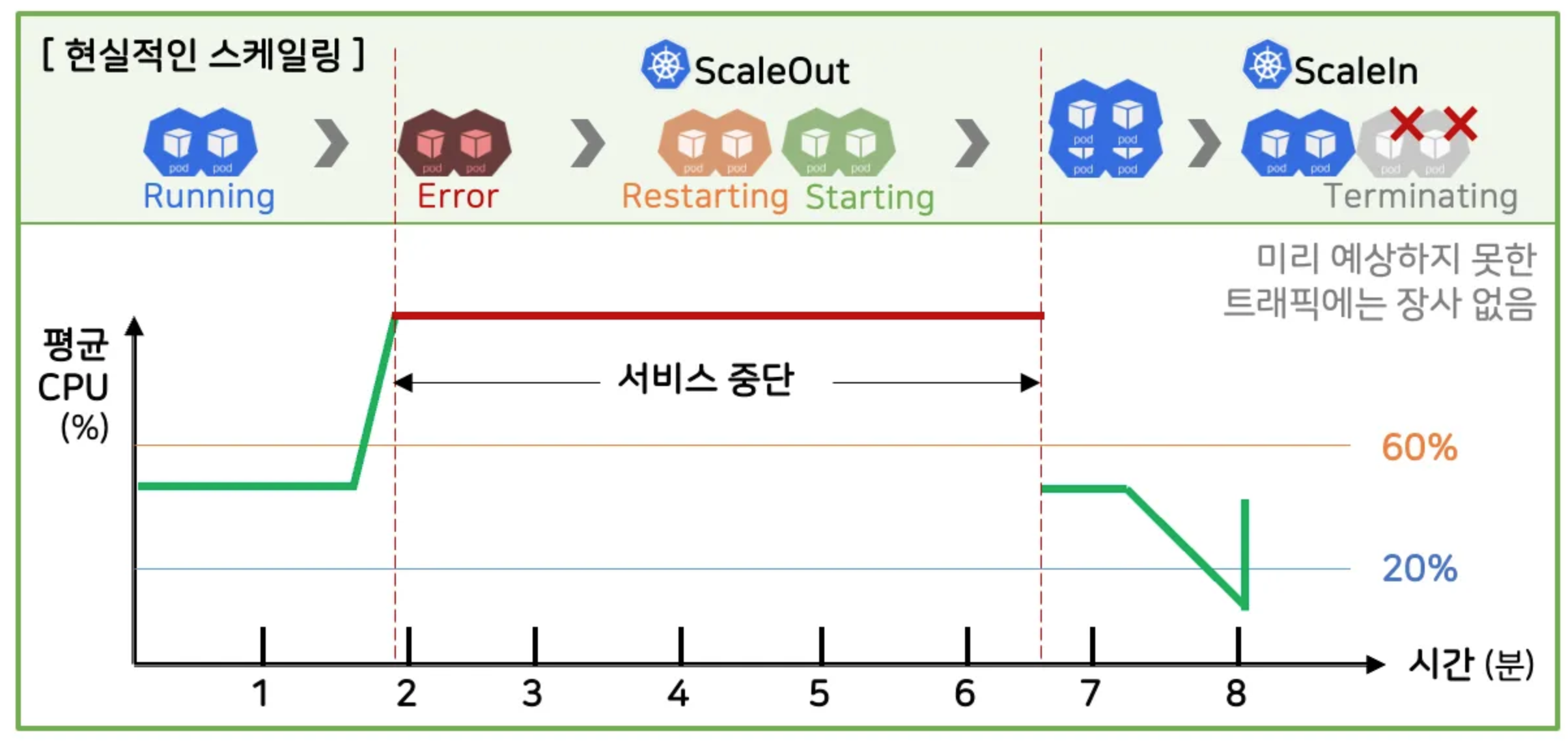
- CPU 가 급격하게 올라가면서 Pod 가 전부 죽는다
- 100%를 넘었기 때문에 스케일아웃
- 기존에 죽은 Pod 는 셀프힐링으로 Restarting
- 스케일 아웃으로 만들어지는 Pod 는 Strating
- Pod 가 뜨는 시간만큼 서비스 중단이 발생
→ 미리 예상하지 못한 트래픽에는 장사가 없다
4-4. behavior
잦은 스케일링을 방지하기 위해서 사용
- 부하가 잠깐 올라가고, 내려가는 상황이 발생
- 스케일 아웃이 되면, 새 Pod 가 만들어지고 바로 죽는 과정에서 cpu 가 비효율적으로 사용
- 안정화 윈도우 설정
stabilizationWindowSeconds: 120 → 2분 동안 cpu 가 60%를 유지해야 스케일아웃 발생
stabilizationWindowSeconds: 600 → 부하가 감소해도 10분동안 Pod 수 대기
4-5. HPA 동작 확인
- 부하 발생 (2분)
- 미적용
- stabilizationWindowSeconds: 120 를 지우고 부하 발생
- 바로 스케일아웃 확인
5. 응용미션
'🌱 인프런 > ⚓ 쿠버네티스 어나더 클래스 (지상편)' 카테고리의 다른 글
| [미션2] Application 기능으로 이해하기 - Probe > 응용과제 (0) | 2025.06.08 |
|---|---|
| (8) Component 동작으로 이해하기 (0) | 2025.06.08 |
| (6) Configmap, Secret 이해하기 (2) | 2025.06.08 |
| (5) Probe 이해하기 (1) | 2025.06.02 |
| (4) Object 그려보며 이해하기 (0) | 2025.05.30 |